On Monday, Anthropic moves automated Claude usage into a separate, capped credit pool. For teams running agents in the background, the subsidy ends. The control problem doesn’t.
On Monday, your agents stop being subsidized
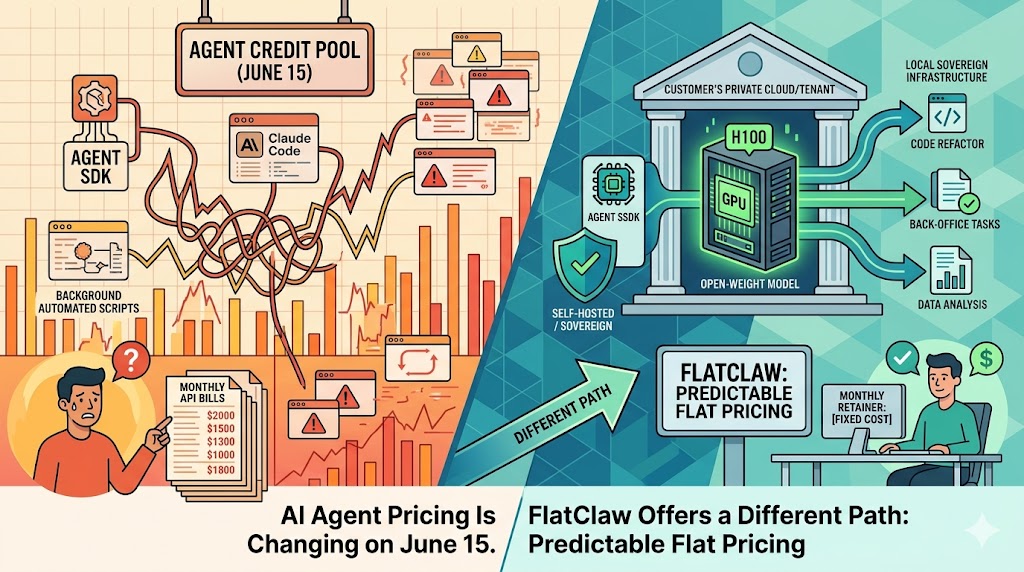
On June 15, 2026, Anthropic moves Agent SDK and automated Claude usage into a separate billable credit pool. claude -p headless runs, Claude Code GitHub Actions, the Agent SDK in Python and TypeScript, and any third-party app that authenticates through the SDK all stop drawing from your subscription’s regular usage pool and start charging against a per-seat agent credit, billed at full API rates. Pro gets $20 a month. Max 5x gets $100. Max 20x gets $200. Enterprise Standard gets nothing. When the credit runs out, automated requests fail unless you have manually enabled overflow billing.
For the teams who have been running agents in the background for months, this is the bill arriving at the door.
The 175:1 subsidy is what is actually ending
Anthropic’s framing is operational, and to be fair it’s not wrong: a human typing into a chat sends dozens of prompts per day; an autonomous coding agent fires thousands, recursively calling models, running tests, retrying on failure. A Max 20x seat extracting up to $35,000 a month of API-equivalent compute on a $200 subscription is a 175:1 ratio that no flat-rate pool was built to absorb at scale. The independent estimates landed in the same place: 12:1 on Pro, 30:1 and up on Max tiers.
Boris Cherny, who runs Claude Code, gave the cleanest official line: the subscriptions “weren’t built for the usage patterns of these third-party tools.” Theo Browne, founder of T3 Code, gave the response his cohort actually feels: “an attack on open-source tooling that repudiates months of explicit promises.” Both can be true. Both are true.
The strategically interesting fact isn’t the move. It’s the lead time. Anthropic gave the developer ecosystem fewer than two weeks to re-plumb its workflows.
Agent traffic is not chatbot traffic
The unsubsidized cost of an agentic workload doesn’t scale linearly. It compounds. A LeanOps analysis this spring measured the multiplier directly: a five-step file-reading task costs 3.2× more tokens than a single chat call; at fifty steps the multiplier passes 30×; at two hundred steps it clears 100×. Each reasoning step re-sends the accumulated context. The token bill is a function of trajectory length, not headcount.
This is why the cautionary tales of the last six months read the way they do. Uber gave roughly 5,000 engineers Claude Code access in December 2025 and burned through its annual AI budget by April. An unnamed enterprise hit a $500M monthly Claude bill, the root cause traced to a single misconfigured token-pricing assumption. A developer in a LeanOps audit cohort ran $4,200 of API charges in a single long weekend on an autonomous refactor. Microsoft, the most public buyer in the cohort, cancelled most of its internal Claude Code seats outright. None of these were bad-faith users. They were working users, running the agents the vendor sold them, against the rate card the vendor published.
The new credit pool doesn’t solve the runaway problem. It just makes sure the explosion happens inside the API meter instead of the subscription pool. Your CFO still gets the dashboard alert. It just arrives one tier higher.
AI agent costs are a control problem
The cleanest framing I have read on this is from Daniel Jindoo’s Substack: agent billing now divides on who initiates the work. Type into a terminal and you are still on the subscription. Hand the same prompt to a scheduled job, a webhook, a CI step, or a third-party tool and you have crossed into the metered lane. The boundary isn’t technical. The boundary is which lane the vendor has decided you belong in this month, and the vendor reserves the right to redraw the lines.
Jindoo’s prescription is a routing system. Frontier for high-leverage thinking. Terminal for cheap human-driven agent work. Local models for repeatable tasks where control matters more than peak intelligence. The framing is the right one. The execution is where most teams have been quietly hoping someone else solves the problem first.
Routing is half the answer. The other half is sovereignty.
If you accept the routing argument, you have to be honest about what the “local” leg of the route actually has to be. It is not a toy. It is not a 7B chat model running on a developer laptop. It has to clear a real production bar: long context, reliable tool calls, frontier-adjacent reasoning, and an operating posture your security team can defend in a procurement review. Anything less and your routing layer collapses back to frontier API as the only path that actually works, and you are back where you started, just with extra complexity.
That bar is now reachable on a single dedicated GPU. A single H100 serving an open-weight 30B-class model in FP8 sustains roughly 1,260 output tokens per second at concurrency 128, supports 8 to 12 concurrent streaming chats, and clears a per-tenant ceiling near 2 billion output tokens per month at 60% utilization. At 70% utilization the realized cost lands near $1.35 per million output tokens. The frontier list price for the same workload, billed against Sonnet 4.6, is around $15. Against Opus 4.7 or GPT-5.5, it’s $25 to $30. The structural delta is 11× to 22×, and it is not waiting on a price war to close. The gap is the venture margin, the spare-capacity overhead, and the orchestration tax stacked on top of the hardware cost.
The rule of thumb that falls out of the math
From the Enterprise Guide we published in June, distilled to one paragraph for the procurement deck:
Below approximately 100 million output tokens per month, the per-token API is almost always correct. Above approximately 1 billion output tokens per month, evaluate self-hosting. The band in between is where data-locality posture, not the cost curve, usually decides.
The June 15 change shifts the threshold downward in two ways. First, every workflow you currently run against your subscription pool now amortizes against the API rate card the moment it moves into the credit lane, which means many more teams will cross 100M output tokens in agent traffic alone. Second, the credit cap is a forcing function: a Pro seat absorbs roughly 1.3M output tokens against Sonnet 4.6 before the meter trips, which is about a single solid week of autonomous coding work for one developer.
If you have one developer running headless Claude Code, you will not feel this. If you have a team of fifty, you will feel it on day two.
What the private answer looks like in practice
We spent the first half of 2026 building this exact substitution, on the route Jindoo’s framework hand-waves through. The harness is OpenClaw, the open-source agent gateway Microsoft now ships as the runtime for Scout, its own enterprise Autopilot product. (Peter Steinberger’s confirmation, reproduced in Alex Heath’s Sources newsletter, was that Scout doesn’t merely look like the OpenClaw gateway; it is the OpenClaw gateway.) The model is Gemma 4 31B-it in FP8, serving on SGLang, with a 256K native context window per session. The retrieval layer is RAGFlow, citing back to the source paragraph. The substrate is a single-tenant Northflank project the customer owns and pays for directly, on a dedicated H100. No vendor sits in the data path at runtime. Egress is zero, mechanically verifiable with a tcpdump on the tenant interface, not a contractual representation.
We call the productized take FlatClaw. The commercial structure mirrors the deployment posture: the customer holds the cloud account, Northflank bills the customer for the GPU, Kirk Tech runs a fixed monthly retainer for implementation and operations. The retainer doesn’t move when the team writes more code. The bill doesn’t move when the agents loop for the weekend.
The relevant property under the new Anthropic regime is the one a CFO will notice first: cost decouples from agent activity. The credit cap problem doesn’t apply, because there is no credit. The runaway-loop problem doesn’t apply, because the marginal cost of another 50,000 retries is zero. The “we just got a $4,200 weekend” problem doesn’t apply, because the GPU was already paid for on Monday.
What to do in the six days you have left
- Inventory your headless surface. Everything that uses
claude -p, the Agent SDK, Claude Code GitHub Actions, or a third-party tool authenticated through the SDK is now metered. Make the list before Sunday. - Turn on overflow billing alerts before you need them. Overflow is off by default. After June 15, automated requests fail when the credit pool empties — no queue, no fallback, no notification. Either enable overflow with a budget alert, or accept the hard stop as a feature.
- Score the workloads on Jindoo’s three lanes. Frontier-required, human-driven-in-terminal, repeatable-and-routine. The third bucket is where the credit-pool change will hurt you most, and it is also the bucket where a private deployment quietly pays for itself.
- Pull the Enterprise Guide and use the five-point test. Where the workload runs, where the data goes, who controls the version, where the logs live, whether the weights are portable. If you fail three of five against your current vendor, you have already made the case internally. The deployment work is mechanical from there.
Public pricing is a control problem. Private deployment is the answer.
Anthropic will not be the last vendor to renegotiate the terms under which agents bill. OpenAI will rebalance its tiers. Google will reframe its enterprise pricing. The shape of the move on June 15 is not unique to one provider; it is the structural consequence of agentic workloads being 30× to 100× more token-hungry than the chat patterns the subscription pools were designed around. Every flat-rate offering in the category will face the same arithmetic, and every flat-rate offering will eventually concede the same way.
The way out is not a better DPA, a tighter contract, or a routing layer that still depends on someone else’s invoice arriving as expected. It is the same answer the Enterprise Guide closes on, in a sentence we have not had reason to change in six months: your project, your bill, your hardware. The intelligence runs on your silicon. The data never leaves. The cost is flat. The CFO sleeps through the weekend.
The harness Microsoft picked for Scout, the same one a regulated mid-market firm can pull off GitHub today, has 180,000 stars and a permissive license. The model weights are open. The serving stack is open. The substrate is leasable by the hour. The only question left is whether you would rather be a credit-pool tenant, or a tenant of your own infrastructure.
Schedule a discovery call
To walk this against a specific workload, book a discovery call at flatclaw.org or kirktechsolutions.com. Bring a workload, a posture, and a volume estimate. We’ll bring the architecture and the honest read on whether a private deployment is the right answer for you.
Sources cited
- Daniel Jindoo, AI Agent Costs Are a Control Problem. danieljindoo.substack.com
- TechTimes. Anthropic Ends Subscription Subsidy for Agents June 15. techtimes.com
- The New Stack. Anthropic splits billing again: Agent SDK gets separate credit pools. thenewstack.io
- Zed Blog. What Anthropic’s New Claude Billing Means for Zed Users. zed.dev
- LeanOps. AI Agents Burn 50x More Tokens Than Chats. leanopstech.com
- Cybernews. Runaway Claude AI usage led to $500 million monthly bill. cybernews.com
- AI Weekly. Microsoft drops Claude Code as enterprise AI ROI fails. aiweekly.co